Cross Validation
"Trust your CV score in Kaggle competitions more than the public LB score."
- Hold-out (standard one 80/20 split)
- K-folds (split data into k folds and each fold would be a validation set)
- Leave-one-out (extreme K-folds)
- Leave-p-out
- Stratified K-folds (useful for imbalanced datasets)
- Repeated K-folds (pick 80/20 split data randomly k times, bad for imbalanced datasets)
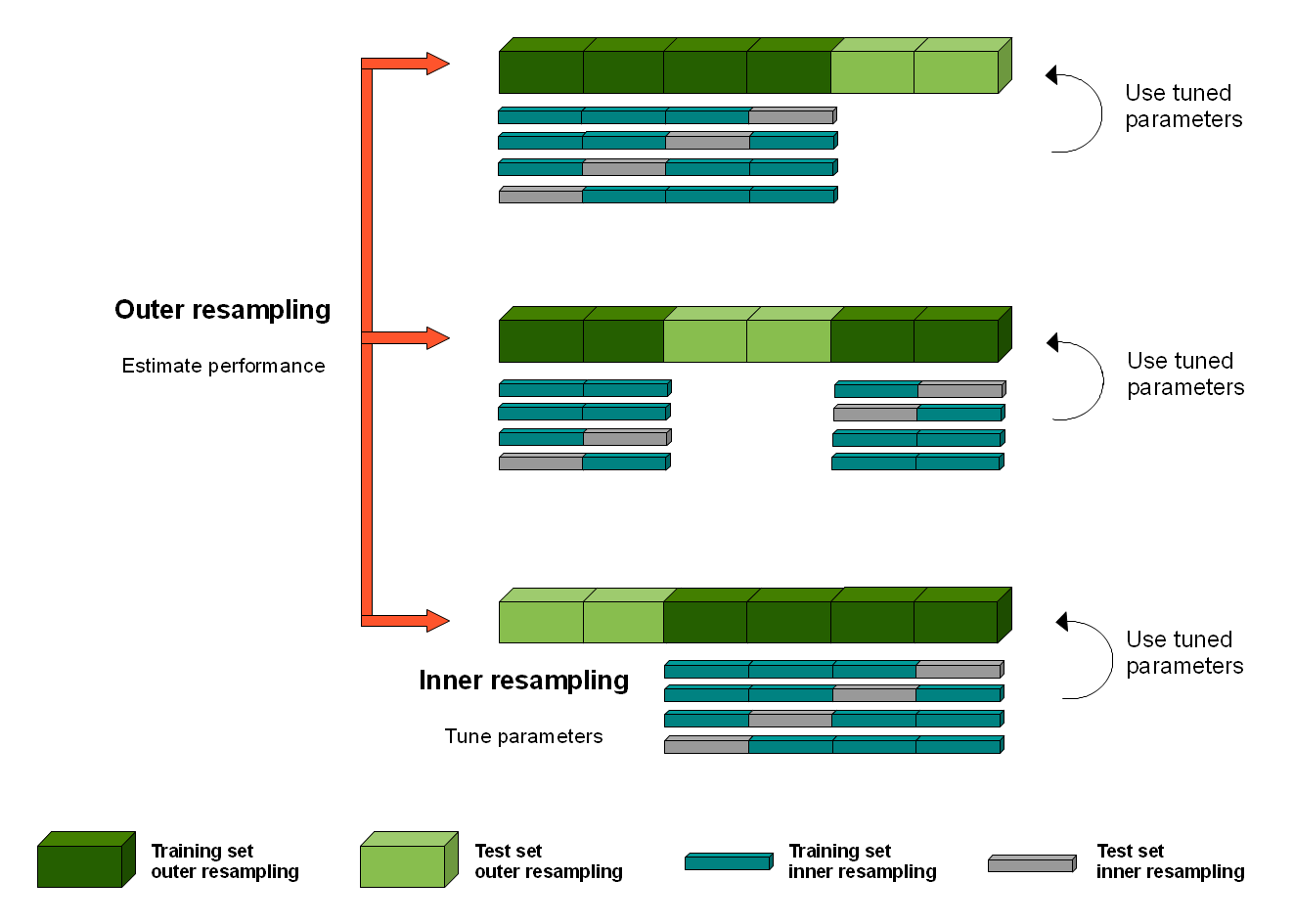
- Nested K-folds: need to implement mannually, good for hyperparameter tuning
- Time series CV (deals with forwardlooking bias in TS data)
from sklearn.model_selection import KFold, GroupKFold
Nested Cross Validation: