SQL
Most notes here are from Stanford lectures and leetcode.
Buzzwords
relational algebra, relational data model, relational database, DBMS (database management system), PostgreSQL, MySQL, declarative, power of set theory, projection, persistent data (outlives program), schema (type) vs data(variables), DDL (data definition language) used to set up schema, DML (data manipulation language = query language), database = set of named relations, relation = table, columns = attributes of relation, rows = tuple, schema = structural description of relations in database, ACID properties, select = project operator, cross product, join, inner, outer, left, right, union, join = cross product + where, CTE = common table expression, subquery, normalization, denormalization, sharding, shards, transactions
- SQL is declarative - you say "what" you want but not how you want it
- SQL is not "Turing complete" = computationally universal (can do all stuff)
- basic SQL cannot run unbounded computations (no for loops)
Code snippets
- join
select *
from table1 t1
left join table2 t2
on t1.id = t2.id
select *
from t1
left join t2 using(product_id)
- no full outer join in MySQL. Emulate it by:
SELECT * FROM t1
LEFT JOIN t2 ON t1.id = t2.id
UNION
SELECT * FROM t1
RIGHT JOIN t2 ON t1.id = t2.id
- join on operations leetcode
sometimes is smart to do joins on operations/conditions
join on t1.id = t2.id-1
-
join is just a cross product with where statements
-
conditional statement case when else end
select
(case
when condition1 then result1
when condition2 then result2
when conditionN then resultN
else result # else can be dropped too
end) as field
from table
- if conditional statement
select if(condition, true_val, false_val) as field
from table
- least, greatest to take min,max of a row leetcode
select least(from_id,to_id) as person1, greatest(from_id,to_id) as person2,
count(*) as call_count, sum(duration) as total_duration
from calls
group by person1,person2
select
datediff(date1,date2) as diff, -- measred in days
period_diff('202210','202301') as diff, -- measured in months
month(date1) as month,
date_add('2018-05-01',INTERVAL 1 DAY) as next_day,
dayofweek('2007-02-03') as day_of_week # 1 to 7 (1 and 7 are weekend)
dayofyear('2007-02-03') as day_of_week,
to_days('2008-01-01') as date_number,
date_format(date,'%d/%m/%Y') as formatted_date,
least('2018-12-31',date),
greatest(d1,d2)
- date_part, date operations in postgresql - give PART of the DATE
- leetcode you can test your functions here
select
DATE_PART('field', column_name) -- need to use these quotation marks ''
SELECT DATE_PART('year', TIMESTAMP '2024-07-06 15:23:10'); -- 2024
SELECT DATE_PART('day', DATE '2024-07-06'); -- 6
SELECT DATE_PART('month', now()); -- current month as number
SELECT DATE_PART('dow', DATE '2024-07-06'); -- 6 (Saturday, 0 = Sunday)
from t
fieldcan be 'year', 'month', 'day', 'dow', 'hour', 'minute', 'second'- 'dow' gives a number where 0 is Sunday and 6 is Saturday
- date_trunc truncates the date column to the specified precision (beginning of month, year and so on)
SELECT DATE_TRUNC('month', TIMESTAMP '2024-07-06 15:23:10'); -- '2024-07-01 00:00:00'
SELECT DATE_TRUNC('day', TIMESTAMP '2024-07-06 15:23:10'); -- '2024-07-06 00:00:00'
SELECT DATE_TRUNC('year', now()); -- start of this year
-
TIMESTAMP, DATE, INTERVAL . they all convert string to date-like object
-
INTERVAL represents a unit of time that can be added or subtracted from dates
INTERVAL 'N unit' -- unit can be 'day', 'days', 'month', 'week', 'hour' etc
SELECT TIMESTAMP '2025-05-01 15:45:01' + INTERVAL '10 minutes',
TIMESTAMP '2025-05-01 15:45:01' - INTERVAL '10 minute' as a,
TIMESTAMP '2025-05-01 15:45:01' + INTERVAL '1 week' as b
- casting in postgreSQL
-
Use ::typename or CAST(value AS typename)
-
If in doubt, cast explicitly.
SELECT '2023-08-16'::date; -- 2023-08-16
SELECT '2023-08-16 15:20'::timestamp; -- 2023-08-16 15:20:00
SELECT '123'::integer; -- 123 (text to int)
SELECT 123::text; -- '123' (int to text)
- width_bucket
select width_bucket(column_name, min_value, max_value, number_of_buckets) -- max_value is the upper bound of the last bucket non-exclusive [)
select width_bucket(score, 1, 101, 5) -- 5 buckets [1,20], [21- 40] ...
- subquery in select statement example leetcode
select contest_id, round(count(*)/(select count(*) from users)*100,2) as percentage
from register
group by contest_id
order by percentage desc, contest_id asc
- where clauses
where field in ('string', 'string1')
where a = 6 or a = 9
where low < a and a < high
- not in operator with null values CAREFUL stackoverflow leetcode 584
MySQL uses three-valued logic -- TRUE, FALSE and UNKNOWN. Anything compared to NULL evaluates to the third value: UNKNOWN. That “anything” includes NULL itself! That’s why MySQL provides the IS NULL and IS NOT NULL operators to specifically check for NULL.
select name
from customer
where referee_id != 2 or referee_id is null
- filling in null values - use the IS operator
case
when field is null then 0 # field = 0 would not work
else field end
IFNULL(field, 0) AS field
- delete
DELETE FROM table_name WHERE condition;
- delete problem, cannot delete from referenced table and need to create a temporary copy
# delete from person
# where id not in (select min(id) from person group by email)
# create temporary copy of table
delete from person
where id not in (select t.id from (select min(id) as id from person group by email) t)
- substring(col_name, start_index, length), length is optional
SELECT SUBSTRING('SQL Tutorial', 1, 3) AS ExtractString;
- union, union all
t1
union
t2 # duplicates are removed
t1
union all
t2 # duplicates are stacked
- between
SELECT column_name(s)
FROM table_name
WHERE column_name BETWEEN value1 AND value2;
- 2388 Change Null Values in a Table to the Previous Value
with cte as (select *, row_number() over() as row_num, if(isnull(drink),0,1) as flag from coffeeshop),
cte2 as (select *, sum(flag) over(order by row_num) as group_id from cte)
select id, first_value(drink) over(partition by group_id) as drink
from cte2
- concatanete two strings
select concat(s1,s2) as combined
from t
- lower case, upper case
select lower(s), upper(s)
from t
- functions in SQL leetcode
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
RETURN (
# Write your MySQL query statement below.
);
END
-limit + offset leetcode
SELECT
column_list
FROM
table1
ORDER BY column_list
LIMIT row_count OFFSET offset;
# The LIMIT row_count determines the number of rows (row_count) returned by the query.
# The OFFSET offset clause skips the offset rows before beginning to return the rows.
# OFFSET is optional
- rank in over(partition by)
RANK ( ) OVER ( [ partition_by_clause ] order_by_clause )
ProductID Name LocationID Quantity Rank
----------- ---------------------- ------------ -------- ----
494 Paint - Silver 3 49 1
495 Paint - Blue 3 49 1
493 Paint - Red 3 41 3
496 Paint - Yellow 3 30 4
- dense rank leetcode
DENSE_RANK ( ) OVER ( [ <partition_by_clause> ] < order_by_clause > )
ProductID Name LocationID Quantity Rank
----------- ---------------------------------- ---------- -------- -----
494 Paint - Silver 3 49 1
495 Paint - Blue 3 49 1
493 Paint - Red 3 41 2
496 Paint - Yellow 3 30 3
- cumulative total
SELECT Id, StudentName, StudentAge,
SUM (StudentAge) OVER (ORDER BY Id) AS RunningAgeTotal
FROM Students
- rolling sum/average
select visited_on,
sum(amount) over(order by visited_on rows between 6 preceding and current row) as amount,
avg(amount) over(order by visited_on rows between 6 preceding and current row) as average_amount
from customer
-
window functions
- sum, avg, first, lead, lag, rank, dense_rank
-
lag window function
select *, lag(purchase_date) over(partition by user_id order by purchase_date) as previous_date
from purchases
- lead, window function for value in the next row
SELECT dept_id, last_name, salary,
LEAD (salary,1) OVER (ORDER BY salary) AS next_highest_salary
FROM employees;
- like, search in substring, patients
select col
from table
where col like '%KUR%'
-
to get island values (group of equal consecutive values in a column) use rank- rank trick, leetcode
-
CAST to datatypes
-- For Sql server
SELECT CAST(25.65 AS int);
/*
CAST(<value_to_cast> AS <data_type_to_cast_to>)
*/
- put stuff in one cell table with group_concat
+------------+------------+
| sell_date | product |
+------------+------------+
| 2020-05-30 | Headphone |
| 2020-06-01 | Pencil |
| 2020-06-02 | Mask |
| 2020-05-30 | Basketball |
| 2020-06-01 | Bible |
+------------+------------+
TO
+------------+----------+------------------------------+
| sell_date | num_sold | products |
+------------+----------+------------------------------+
| 2020-05-30 | 3 | Basketball,Headphone,T-shirt |
| 2020-06-01 | 2 | Bible,Pencil |
| 2020-06-02 | 1 | Mask |
+------------+----------+------------------------------+
# Write your MySQL query statement below
select sell_date, count(distinct product) as num_sold,
group_concat(distinct product order by product separator ',') as products
from activities
group by sell_date
- pivot trick student by geography
# Write your MySQL query statement below
select max(case when continent = 'America' then name end) as America,
max(case when continent = 'Asia' then name end) as Asia,
max(case when continent = 'Europe' then name end) as Europe
from
(select *, row_number() over(partition by continent order by name) as rn
from student) t
group by rn
-- static pivot
-- select product_id,
-- sum(case when store = "store1" then price end) as store1,
-- sum(case when store = "store"then price end) as store2,
-- ....
-- from products
-- group by product_id
-- this procedusre would concatenate all select statements in case_stmtsum(..)
CREATE PROCEDURE PivotProducts()
BEGIN
# Write your MySQL query statement below.
SET SESSION group_concat_max_len = 1000000;
--define case statement
select group_concat(distinct concat('sum(case when store = "',store,'" then price end) as ', store))
into @case_stmt
from products;
-- get whole sql query
set @sql_query = concat('select product_id, ',@case_stmt, ' from products group by product_id');
prepare final_sql_query from @sql_query;
execute final_sql_query;
deallocate prepare final_sql_query;
END
- delimit identifiers, ignore special symbols, characters, spaces etc
select *
from [my table]
where [order] = 10
- index column
CREATE INDEX [index name] ON [table name] ( [column name] )
-transactions
BEGIN TRANSACTION
BEGIN TRY
UPDATE table_name SET BAKIYE = BAKIYE - 1000
WHERE Name='Name' AND Surname='Surname'
UPDATE table_name SET BAKIYE = BAKIYE + 1000
WHERE Name='Name' AND Surname='Surname'
update salary set sex = if(sex ='f','m','f')
-- swap f to m and m to f in sex column
COMMIT
END TRY
BEGIN CATCH
ROLLBACK
END CATCH
SQL Variables
If we want to use a variable in SQL Server, we have to declare it using DECLARE statement.
Local variable names have to start with an at (@) sign.
- declaring variables
DECLARE @TestVariable AS VARCHAR(100)
DECLARE @TestVariable -- NULL initialization
- assign values to variables
SELECT @TestVariable = 'Save the Nature' --single select line
--- ASSIGN LAST VALUE OF TABLE T
select @TestVariable = person_name
from t
where salary = 100000
- assign variable value using set
DECLARE @Variable1 AS VARCHAR(100)
DECLARE @Variable2 AS UNIQUEIDENTIFIER
SET @Variable1 = 'Save Water Save Life'
SET @Variable2= '6D8446DE-68DA-4169-A2C5-4C0995C00CC1'
- assign many varaibles to values
DECLARE @Variable1 AS VARCHAR(100), @Variable2 AS UNIQUEIDENTIFIER
SELECT @Variable1 = 'Save Water Save Life' , @Variable2= '6D8446DE-68DA-4169-A2C5-4C0995C00CC1'
- end of batch,
GOkeyword
DECLARE @TestVariable AS VARCHAR(100)
SET @TestVariable = 'Think Green'
GO
PRINT @TestVariable -- ERROR, varibale not declared
- PREPARE, EXECUTE and DEALLOCATE statement in MySQL
- running strings as statements
SET @s = 'SELECT ? + ? AS sumtable';
PREPARE stmt1 FROM @s;
SET @a = 4;
SET @b = 6;
EXECUTE stmt1 USING @a, @b;
DEALLOCATE PREPARE stmt1;
this would return
+----------+
| sumtable |
+----------+
| 10 |
+----------+
SQL CTE
CTE = Common Table Expression. These are temporary tables which act as variable that you can use through your code. Example problem
with cte as (select *,rank() over(order by money) as r from t),
cte2 as (select *,min(r) as minn from cte2),
cte3 as (select student from cte2 where r = minn)
select *
from cte3
Avoid running lots of subqueries, joining, carrying tables around!
SQL recursion
Basic SQL cannot express unbounded computations.
Table: ParentOf
Parent | Child
Sue | Mary
Bob | Mary
Fred | Bob
Jane | Bob
Tasks: Find Parent, Grandparent (two instances of ParentOf), Grand-grand parent(three instances of ParentOf) Note you need recursion
With construct exists in SQL by itself. It often used to have recursion in SQL.

each relation R is the result of its corresponding query. Final result of the master LAST query. Can thing of AS to be an
assignment for the realtions
We can specify recursive statements using the Recursive keyword after With
WITH RECURSIVE cte_name AS (
initial_query -- anchor member
UNION ALL
recursive_query -- recursive member that references to the CTE name
)
SELECT * FROM cte_name;
WITH RECURSIVE cte_count
AS (
SELECT 1 as n-- BASE CASE
UNION ALL # might enter infinite loop, careful
SELECT n + 1
FROM cte_count -- Recursive call, should dependt on the relation itself CTE_COUNT!
WHERE n < 3
)
SELECT n
FROM cte_count;
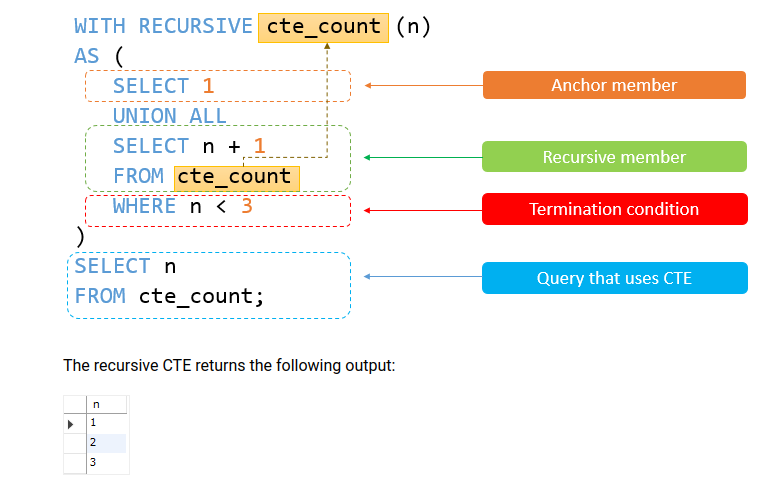
- generate consecutive numbers
WITH RECURSIVE seq AS (
SELECT 0 AS value UNION ALL SELECT value + 1 FROM seq WHERE value < 100
)
SELECT * FROM seq;
- with statement leetcode Basic SQL cannot express unbounded computations. WITH construct is available in SQL without recursion. But this is the construct used to ADD recursion in SQL. CTE = common table expression. WITH is like a function in SQL
with R1 as (query 1),
R2 as (query 2),
...
CTE as (query),
<query involving all R1, R2 ..Rn, CTE + other tables> # return this last query
- recursion
WITH RECURSIVE cte_name AS (
cte_query_definition (the anchor member)
UNION ALL
cte_query_definition (the recursive member) # often need where statement to stop
)
SELECT *
FROM cte_name;


- classic family tree recursion problem
SQL indexing
Index column B and you can ask questions such as show me the rows where elements in column B belong to certain interval is going to be faster.
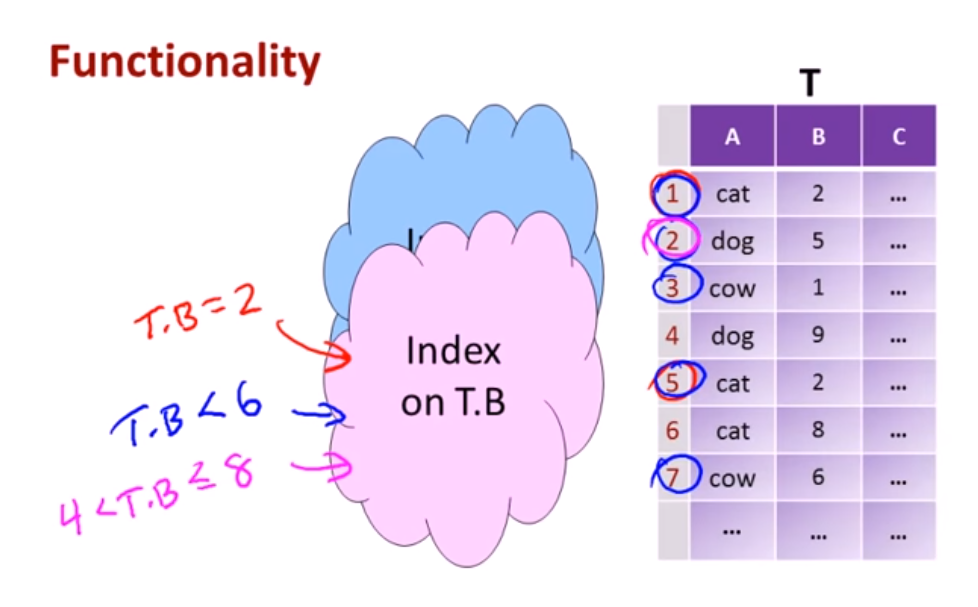
Users don't access indexes! They are used underneath by the query execution engine.
Underlying data structures = type of indexes:
- hash allows only concrete checks such as table.A = val O(1)
- B+ trees allows checks such as table.A = val, v1 < table.A <= v2 O(log(n))
- R+ trees
No indexes is O(n) time
Many DBMS's build indexes automatically on PRIMARY KEY (and sometimes UNIQUE) attributes.
Examples:
select student_id
from student
where student_name = 'Kuny' and gpa > 3.9
- index on student_name (hash-based index)
- index on gpa (tree-based)
- index on (student_name,gpa)
select s_name, c_name
from student, apply
where student.s_id = apply.s_id
- no indexing is
O(m*n) - index student.s_id ->
O(n) - index apply.s_id ->
O(m)
Downsides of indexes:
- extra space (persistent data structure stored underneath the database) = marginal downside (ok-ish)
- index created = medium downside/initialization can be slow
- index maintenance, can offset benefits. If we modify often the const of maintaining the indexes (re-initialization) can be quite expensive. If you do lots of writes and less reads better not use indexes.
create index your_index_name on your_table_name(your_column_name) using HASH;
or
create index your_index_name on your_table_name(your_column_name) using BTREE;
The best way to improve the performance of SELECT operations is to create indexes on one or more of the columns that are tested in the query. The index entries act like pointers to the table rows, allowing the query to quickly determine which rows match a condition in the WHERE clause, and retrieve the other column values for those rows. All MySQL data types can be indexed. Indexes are used to find rows with specific column values quickly. Without an index, MySQL must begin with the first row and then read through the entire table to find the relevant rows.
- index columns used in
WHEREclauses
Column Indexes
The most common type of index involves a single column, storing copies of the values from that column in a data structure, allowing fast lookups for the rows with the corresponding column values. The B-tree data structure lets the index quickly find a specific value, a set of values, or a range of values, corresponding to operators such as =, >, ≤, BETWEEN, IN, and so on, in a WHERE clause.
Database design
-
Understand the Data – Is it relational or document-based? Do you need to manage complex queries or just store simple key-value pairs?
-
Scalability Is Key – High traffic? Complex joins?
-
Consistency vs. Performance – Do you need strong consistency (ACID) or can you tolerate eventual consistency for better availability and partition tolerance?
-
Account for Future Evolution – Can your database scale? Is it flexible enough for new features?
-
Keep It Simple
- start with 'mega' relations containing everything
- decompose into smaller, better relations with same info
- can do decomosition automatically Final set of relations satisfies normal form (normalization of a database) = no redundant data, updates are easier to be made.
Denormalised database example:
Apply(SSN, student_name, college_name, high_school, city, hobby)
Apply is a table with all columns (ssn = social security number) stored in one place. To record Ann with SSN = 123 from Sofia, studied at SMG and 125, plays tennis and trumpet and applied at Stanford, Berkeley, MIT we need 12 different rows! Studied at SMG will be repeated 6 times, applied at MIT will be repeated 4 times. Redundancy in the database.
Normalised database:
Student(SSN, student_name)
Apply(SSN, college_name)
HighSchool(SSN, high_school)
Located(high_school, city)
Hobbies(SSN, hobby)
Decide how to normalize your database by looking for:
- functional dependencies
- multivalued dependencies
Buzz word If you see Functional Dependency use Boyce-Codd Normal Form (decompose your table)

Buzz word If you see multivalued Dependency use Boyce-Codd Normal Form (decompose your table)

Maybe check this youtube
ORM
SQL Alchemy
ORM
Relational Map, e.g. from SQL to Python
leaky/soft abstraction
Problems
1285 177 571 1709 1270 1613 569 608 2308 2228 1285 1369
Topics
Space and Time Complexity intro to Queries: https://medium.com/learning-data/understanding-algorithmic-time-efficiency-in-sql-queries-616176a85d02
Basic (important!) Query Optimisation Techniques: https://medium.com/learning-sql/12-tips-for-optimizing-sql-queries-for-faster-performance-8c6c092d7af1
Advanced Topics in SQL: https://sqlpad.io/tutorial/advanced-sql/
- UNION, GROU[ BY (UNDERSTAND HOW IT WORKS), INDEXATION, PARTITION
B-TREE: https://builtin.com/data-science/b-tree-index (fundamental Database data structure! - connection to indexing!)