Statistics
Buzzwords
random sample = iid = independent and identically distributed
sum of normal distributions is normal
sum of jointly normal distributions is normal
unbiased estimator (sample variance) divides by to have unbiased estimator of the TRUE variance
MLE = maximum likelihod estimator
likelihood function
If you parametrize in Geometric distribution and find MLE for you will have unbiased MLE! The MLE for is not unbiased (its overestimating)
Introduction. Random samples. Summary Statistics, MLE
Probability: in probability we start with a probability model , and we deduce properties of .
E.g. Imagine flipping a coin 5 times. Assuming that flips are fair and independent, what is the probability of getting 2 heads?
Statistics: in statistics we have data, which we regard as having been generated from some unknown probability model . We want to be able to say some useful things about .
Definition. A random sample of size is a set of random variables which are independent and identically distributed (i.i.d.).
often you will compute the joint pmf of . This joint pmf gives you the probability you observe the sample data ,
In probability we assume that parameters and in our two examples are known. In statistics we wish to estimate and from data.
- What is the best way to estimate them? And what does “best” mean?
- For a given method, how precise is the estimation?
Sample mean and Sample variance, sample standard deviation
Denominator in sample variance is , so that the sample variance will be what is called an unbiased estimator of the population variance. If we divide by our sample variance would be underestimating the TRUE variance on average. We need to divide by the degrees of freedom, not the number of samples! stack _ Given observations we can compute the observed values and .
We use sample mean, variance, standard deviation to estimate the TRUE unknown mean, variance, standard deviation.

MLE = Maximum Likelihood Estimation Maximum likelihood estimation is a general method for estimating unknown parameters from data.
Definition. Let have joint p.d.f./p.m.. Given observed values of the likelihood of is the function:
is the joint pmf, pdf of the observed data and is regarded as a function of for fixed .
Definition. The maximum likelihood estimate (MLE) is the value that maximizes the likelihood (or log-likelihood).
The idea of maximum likelihood is to estimate the parameter that gives the greates likelihood to the obsrvations .
Estimator:
- A rule for constructing an estimate.
- A function of the random variables involved in the random sample.
- Itself a random variable. Estimate:
- The numerical value of the estimator for the particular data set.
- The value of the function evaluated at the data .
Parameter estimation
Definition. A statistic is any function of that does not depend on .
Definition. An estimator of is any statistic that we might use to estimate .
Definition. is the estimate of obtained via from observed values .
We can choose between estimators by studying their properties. A good estimator should take values close to the TRUE parameter .
Definition. An estimator is unbiased for if . This means that “on average” is correct.
Definition. The mean squared error (MSE) of an estimator is defined by
Definition. The bias of is defined by .
MSE is a measure of the “distance” between and the true parameter
However and may depend on .
Note (bias variance trade-off)
So an estimator with small MSE needs to have small variance and small bias.
MLEs are usually asymptotically unbiased, and have MSE decreasing like for large .
USE MSE(T) to compare different estimators for .
Accuracy of estimation: Confidence Intervals
A crucial aspect of statistics is not just to estimate a quantity of interest, but to assess how accurate or precise that estimate is. One approach is to find an interval, called a confidence interval (CI) within which we think the true parameter falls.
Definition. If and are two statistics, and , the interval is called a confidence interval for with confidence level if, for all :
The interval is called an interval estimate and the random interval is called an interval estimator.
Note: and do not depend on .
We want small intervals and to be large.
By the same argument as before, if with known, then a level confidence interval for is
The more data I have the smaller interval I get!
if variance is unknown use SAMPLE VARIANCE (division by ).
Interpretation of a Confidence Interval
- The parameter is fixed but unknown.
- If we imagine repeating our experiment then we’d get new data, say, and hence we’d get a new confidence interval . If we did this repeatedly we would “catch” the true parameter value about of the time, for a confidence interval: i.e. about 95% of our intervals would contain .
- The confidence level is a coverage probability, the probability that the random confidence interval covers the true θ. (It’s a random interval because the endpoints are random variables.)
You always get confidence interval estimates. You cannot say is 95\% confidence interval. It either does or does not contain the TRUE parameter . You cant say which as is unknown.
Confidence Intervals using the CLT
(estimate ± 2 estimated std errors)is an approximate 95% CI (estimate ± 3 estimated std errors)is an approximate 99.8% CI.
Example. Estimating the TRUE variance and stadard deviation of the sample population.
- Let be iid. Then and estimate of the variance is and standard deviation
The variance and SE of an estimator might themself depend on anothe paramater. We need to plug in with the Maximum likelihood estimator (divides by ) or other estimate (sample variance divides by and is unbiased).
Given a radnom normally distributerd sample, when constructing a confidence interval you should use the sample variance. If you use the MLE to estimate the you will underestimate the variance and your CI would be shrinked
Linear Regression
Suppose we measure two variables in the same population:
- : the explanatory variable, predictor, feature, input
- : the response variable, output
A linear regression model for the dependence of on is:
where:
- are known constants (data points)
- are i.i.d. "random errors"
- are unknown parameters. The “random errors” represent random scatter of the points about the line , we do not expect these points to lie on a perfect straight line.
Note: a linear relationship like this does not necessarily imply that causes .
Goal: estimate and
Maximize the likelihood . Same as minimizing the square error !
Vectorized linear regression problem: Estimate for (intercept is included as a col of ones)
Vectorized solution it is an unbiased estimator!
95\% CI for the true parameter is
The standard deviation of the true parameter is usually unknown and we need to estimate it.
You can use the The MLE: to get 95\% CI:
A better approach is to estimate using because this is an unbiased estimator (on average you are correct) and to base the confidence interval on a chi square-distribution rather than a normal distribution. (t-distribution in univariate case is one dimensional and p = 1, division by in this case)
Assessing model fit
Having fitted a model = estimated the parameters .
Having fitted a model, we should consider how well it fits the data. A model is normally an approximation to reality: is the approximation sufficiently good that the model is useful?
Definition. The i-th fitted value is
The i-th residual is
The RSS (residual sum of squares) is
The RSE (residual standard error) is (this is an estimate of the standard deviation ).
Potential problem: non-linearity
A residual plot is a useful graphical tool for identifying non-linearity: for simple linear regression we can plot the residuals against the fitted values . Ideally the plot will show no pattern. The existence of a pattern may indicate a problem with some aspect of the linear model.
Potential problem: non-constant variance of errors
Non-constant variance is also called heteroscedasticity. Can see funnel-type shape in the residual plot.
How might we deal with non-constant variance of the errors?
- One possibility is to transform the response Y using a transformation such as or (which shrinks larger responses more), leading to a reduction in heteroscedasticity.
- If you know how variances behave for and think you can take the approach called weighted least squares minimizing
Potential problem: outliers
An outlier is a point for which is far from the value predicted by the model.
If we believe an outlier is due to an error in data collection, then one solution is to simply remove the observation from the data and re-fit the model. However, an outlier may instead indicate a problem with the model, e.g. a nonlinear relationship between and , so care must be taken.
studentized residuals = standardized residuals greater than 3 is signal for outlier
Potential problem: high leverage points
(Trailstone group interview...)
Outliers are observations for which the response is unusual given the value of .
On the other hand, observations with high leverage have an unusual value of .
Definition the leverage of the ith observation is where
$h_{i} = \dfrac{1}{n} + \dfrac{(x_i - \bar{x})^{2}}{\sum (x_j-\bar{x})^{2}}
Take-away: Points with high residuals pull the regression line towards them more than points with lower residuals (the more are wrong the more the line goes towards them)
Points with unusual value of far from the mean pull ht regression line a lot too. These are called high leverage points.
Why does this matter? We should be concerned if the regression line is heavily affected by just a couple of points, because any problems with these points might invalidate the entire fit. Hence it is important to identify high leverage observations.
Data Analysis
Linear regression is an example of supervised learning .
In unsupervised learning you have only . In this case you want to answer questions:
- Can we find a way to visualize the data that is informative?
- Can we compress the dataset without losing any relevant information?
- Can we find separate subgroups (or clusters) of observations that de- scribe the structure of the dataset?
Unsupervised learning can be more challenging than supervised learning, since the goal is more subjective than prediction of a response variable.
Exploratory data analysis is unsupervised learning.
data matrix = design matrix
First step in modelling - EDA
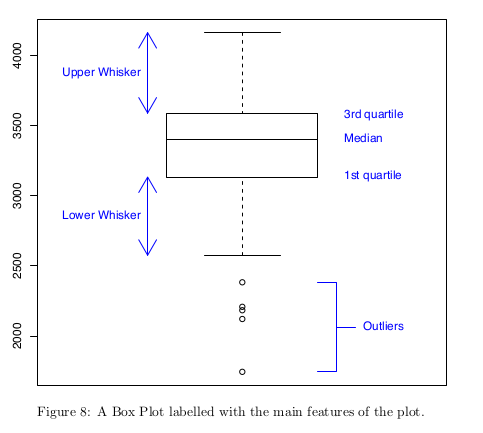
Inter Quartile Range (IQR) - the difference between the 1st and 3rd quartiles. This is a measure of ‘spread’ within the dataset.
Box plot.
Pair plots
3D interactive plots
Simulation is a technique for generating pseudo-random values that have a particular distribution.
The Multivariate Normal Distribution

Given a sample of observations , the MLE-s are:

PCA
Principal components analysis (PCA) finds a low-dimensional representation of the data that captures as much of the information in the dataset as possible.
PCA key points:
- each component coming from PCA is a linear combination of the variables
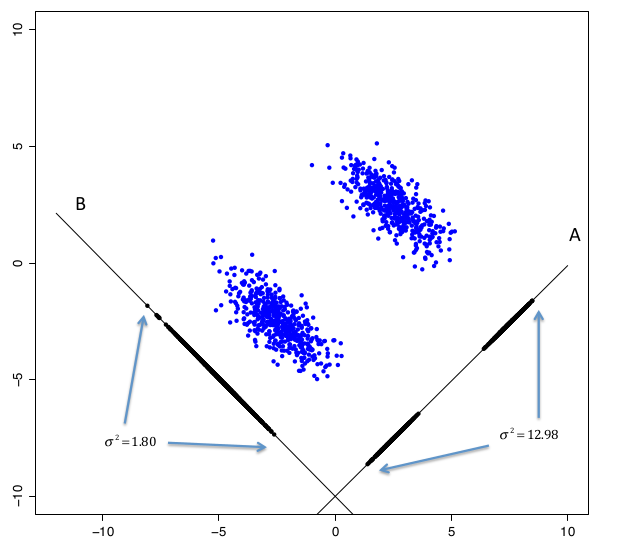
- each components looks for maximum varaibility in the data
components choose a good way to choose a projection that separates the two clusters
PCA is maximization problem. Tofind componene :
subject to
We try to maximize the sample variance of the first component. Solve this using Lagrange Multipliers.
Using vector calculus you will get:
- is the eigen vector with largest eigen value
The way PCA algo work is by doing an eigendecomposition of the sample variance matrix , where is diagonal matrix with the eighen values and is orthonormal/orthogonal and has the eigenvectors of
Plotting
If we define to be an matrix containing the transformed data, such that is the value of the th principal component for the th observation
We can then plot the columns of Z against each other to visualize the data as represented by those pairs of principal components. The matrix Z is known as the scores matrix.
Biplots shows pair of PC-s how they cluster the data. It uses the data projection on the principal components.
The total amount of variance in the original data matrix X is the sum of the diagonal entries in .
It is common practice to plot the decreasing sequence of eigenvalues to visualize ths structure in the dataset. Such plots are sometimes refered to as eigenspectrum plots or variance scree plots, and usually they are scaled so each bar is percentage of the total variance.
Question
Apply PCA to raw data or to transformed data?
The first principal component maximises the variance of a linear combination of variables. If the variables have very different levels of variability then maximizing the projection with the largest variance may tend to dominate the first principal component.
For this reason, it can sometimes make sense to standardize the variables before PCA
This can be achieved by applying PCA to the sample correlation matrix R, rather than the sample covariance matrix S.
It can be shown (see Exercises) that the PCA components derived from using S are not the same as those derived from using R, and knowledge of one of these sets of components does not enable the other set to be derived.
PCA via SVD
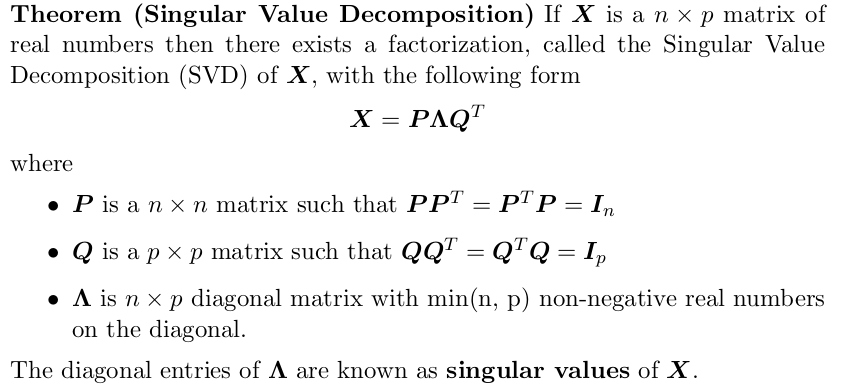
Express design matrix using SVD and rewrite .
You can win on computation time if .
Calculating the eigendecomposition of scales like which is much less than the eigendecomposition of which scales like .
PCA as minimizing reconstruction error
There is another way to derive principal components analysis that uses the idea that we might try to find the low-dimensional approximation that is as close as possible to the original data.
data compression
Clustering
PCA provides low dimensional represeantaion of the data and show groupings of observations when visualized. It does not provide labelling.
Clustering refers to a very broad set of techniques for finding subgroups, or clusters, in a dataset.
K-means
To perform -means clustering we must first decide upon the number of clusters . The algorithm will assign each observation to excatly one of the clusters.

Goals:
- minimize within distance between points in same cluster
- maximize distance between observations from different clusters
K-means algo explicitly tackles the first goal by finding a local minimum. Finiding global minimum would require goind through all partitions of elements in subsets which is factoriel like (Stirling numbers).
The two goals above are actually equivalent see
K means objective function:
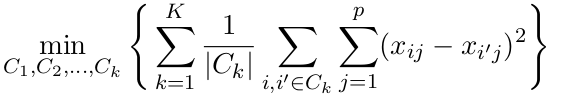
Multiple starts
The algorithm does not always give the same solution since the start point is random.
is overfitting
Hierarchical clustering

Dendrograms can be used to cluster observations into a discrete number of clusters or groups
Different ways to create a hierarchy. Here we consider agglomerative clustering approache.
-
Begin with observations and a measure of all the pairwise dissimilarities, denoted for . These dissimilarities can be represented in a lower diagonal matrix, denoted .
-
For
- (a) Find the pair of clusters with the smallest dissimilarity. Fuse these two clusters.
- (b) Compute the new dissimilarity matrix between the new fused cluster and all other remaining clusters and create an updated matrix of dissimilarities .
Distance betwwen two clusters:
single linkage = minimum (closest) distance betwwen elements from the two clusters
complete linkage = maximum ...
group average =
Problem Sheets
Sheet 1
Q1. Proove that is unbiased estimator of the TRUE variance
Q2. Given data
i) - MLE with known :
ii) Mle negative binomial (different representaion)
iii)
Q3.
i)
ii)
Q4.
i) mgf to prove normality,
ii) ..
iii)
Q5.
Proof is normal using moment generating functions
Sheet 2
Q1.
If you parametrize in Geometric distribution and find MLE for you will have unbiased MLE! The MLE for is not unbiased (its overestimating)
Q2. maximize likelihood
Q3. \hat{p} = \dfrac{\sum x_i}{\sum v_i]
Q5.
a)
b)
i) by definition of distribution - just maximize the likelihood
ii) integrate the pdf from y to inf
iii rewrite the modulus (open it up to use ii)
Sheet 3
Q1. $ (\bar{X}-\dfrac{z{0.025}}{\sqrt(n)},\bar{X}-\dfrac{z{-0.025}}{\sqrt(n)})$
Q2.
i)
ii)
iii) (0.48,0.76) neshto takova
Q3. use 95\% CI
where using the MLE of Theta (poisson MLE)
Q4.
MLE is , then use
Q5.
a) straight
b) mean
c) , but are dependent! Need to compute the bivariate normal distribution.